

Bonsoir,
Je travaille sur un dataset contenant des informations sur des films/ TV-show sur Netflix. Je laisse le lien vers ce dataset:
netflix_titles (2).rar
Je veux faire une analyse factorielle sur ces données et tracer un nuage d'individus. J'ai fait plusieurs tentatives et j'ai trouvé des résultats mais je ne sais pas quoi améliorer.
En fait, le dataset contient des données numériques et non numériques (numerical and categorical variables). J'ai choisi d'enlever plusieurs colonnes et je me suis retrouvé finalement avec trois colonnes: type,rating,listed_in. J'ai One-hot encode la colonne listed_in. J'ai également géré les données manquantes. Bref, le nouveau dataset me parait pret pour y appliquer l'algorithme de MCA. C'est ce que j'ai fait:
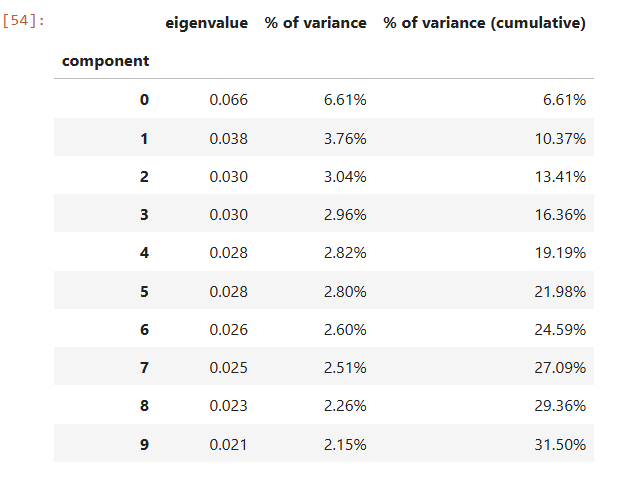
je trouve le résultat suivant:Code:mca = prince.MCA( n_components=5, n_iter=50, copy=True, check_input=True, engine='sklearn', random_state=42 ) mca = mca.fit(data) one_hot = pd.get_dummies(data) mca_no_one_hot = prince.MCA(one_hot=True) mca_no_one_hot = mca_no_one_hot.fit(one_hot) mca.eigenvalues_summary
resultats.png
Ce qui veut dire que les deux premières composantes n'expliquent que 10% de la variance. Une representation plane ne sera pas trop fidèle à la réalité des choses.
Qu'est ce que vous proposez comme solution ? J'ai essayé de mélanger les variables et d'utiliser la FAMD mais cela ne marche pas. Veuillez m'aider pour améliorer le pourcentage d'explicabilité de la variance.
Merci d'avance.
-----

{kind=link}