


Bonjour,
j'ai commencé la lecture de Elements of Statistical Learning (pdf gratuitement disponible ici http://www-stat.stanford.edu/~tibs/ElemStatLearn/)
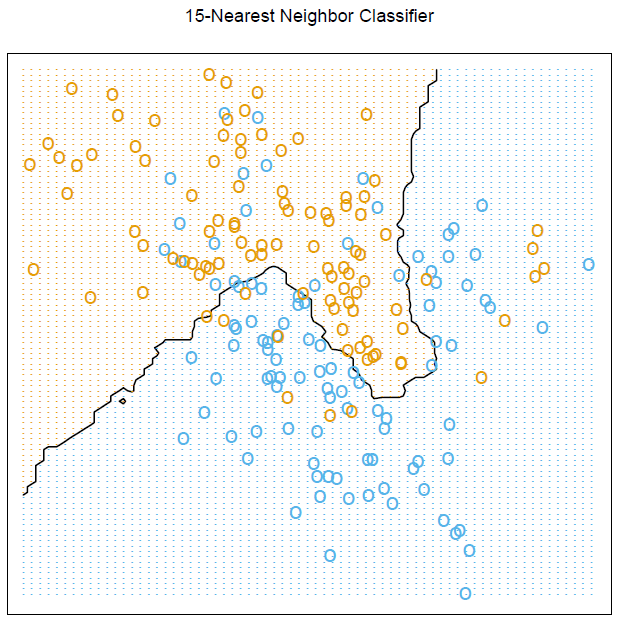
Je ne comprends pas comment est obtenu la figure de la page 15 :
Ils attribuent aux points orange la valeur 1 et aux bleu la valeur 0.
Ils calculent la moyenne des valeurs (1 ou 0 suivant la couleur) des 15 plus proches voisins (il s'agit de la méthode des k-Nearest Neighbors) pour trouver une courbe qui délimite les deux ensembles (points orange et bleu).
Apparemment ils obtiennent le graphe ci-dessus.
Je ne vois pas comment il est possible que la courbe "revienne en arrière" comme c'est le cas sur l'image (si on suit la courbe noire de la gauche vers la droite, on repart vers les x décroissants dans la dernière portion de la courbe).
Il y a donc deux ordonnées associées à une même abscisse.
Je ne vois pas comment la méthode des k-Nearest Neighbors peut aboutir à ce résultat.
-----
