

Bonjour,
Je cherche à implémenter dans Matlab un algorithme permettant de déterminer résoudre un réseau de tuyauterie (c'est à dire déterminer le débit Q et la direction du flux dans chaque tuyau ainsi que la hauteur piézométrique H à chaque intersection).
Le système se présente comme suit:
Schéma réseau A.jpeg
Les longueurs et diamètres des tuyaux sont connus ainsi que leur rugosité (qui est la même pour tous). On négligera les pertes mineures ainsi que l'énergie cinétique de l'eau.
Les deux réservoirs aux embranchements 2 et 3 ont une hauteur piézométrique connue et considérée comme invariante. Les flux sortants sont également connus aux intersections I, IV et VII.
L'algorithme est le suivant:
1- Première estimation des valeurs Q et H + estimation arbitraire de l'orientation des flux (correspond aux flèches bleues sur le schéma). Ces orientations sont consignées dans une matrice de connectivité c.a.d une matrice ayant autant de colonnes qu'il y a d'embranchements et autant de lignes qu'il y a de tuyaux. Les éléments de cette matrice valent 1 là d'où le flux part pour un tuyau donné, -1 là où il arrive et 0 partout ailleurs. Cette matrice sappellera E.
2- Calcul de la vitesse d'écoulement v dans chaque tuyau à partir de Q=(pi*D^2/4)*v
3- Calcul du nombre de Reynolds pour chaque tuyau
4- Utilisation de la formule de Colebrook pour déterminer le coefficient de Darcy (pour la première utilisation de la formule, j'utilise une valeur du coefficient de Darcy correspondant à un nombre de Reynolds tendant vers l'infini c.a.d.
lambda=0.25/( log(eps/3.71)^2 ) )
5- Pour chaque tuyau, je calcule la valeur K=lambda/(2*g*A^2) * L/D * abs(Q) puis je crée une matrice diagonale (les K(i) formant donc une diagonale avec les autres éléments de la matrice égaux à 0)
6- On peut alors obtenir une nouvelle matrice M=E' * inv(K) * E qui présente l'avantage de vérifier l'équation suivante:
M*H=C où C désigne la somme des débits à chaque embranchement
7- Il faut alors distinguer les croisements où on connait H (II et III) et ceux où on connaît H (tous les autres).
On va construire deux nouvelles matrices. Pour chaque embranchement i :
A: - Quand C est connu, la colonne i de A est égale à la colonne i de M
- Quand H est connu, l'élément A(i,i) vaut -1 et le reste de la colonne vaut 0
b:Il s'agit un vecteur. Chaque b(i) prend initialement la valeur -1*Somme(M(i,j)*H(j)) (somme des M(i,j)*H pour tous les H connus)
- Quand C est connu, b(i)=b(i)+C
- Quand H est connu, passer à l'élément suivant
8- On peut alors résoudre A*x=b où x est un vecteur contenant pour chaque embranchement:
C si H était connu
H si C était connu
9- Je ré-obtiens alors le vecteur Q via l'équation Q=inv(K)*E*H
10- Je calcule la déviation relative par rapport à l'itération précédente ainsi que le résidu et compare à une tolérance, l'algorithme boucle alors jusqu'à ce que l'une de ces valeurs soit reconnue comme satisfaisante
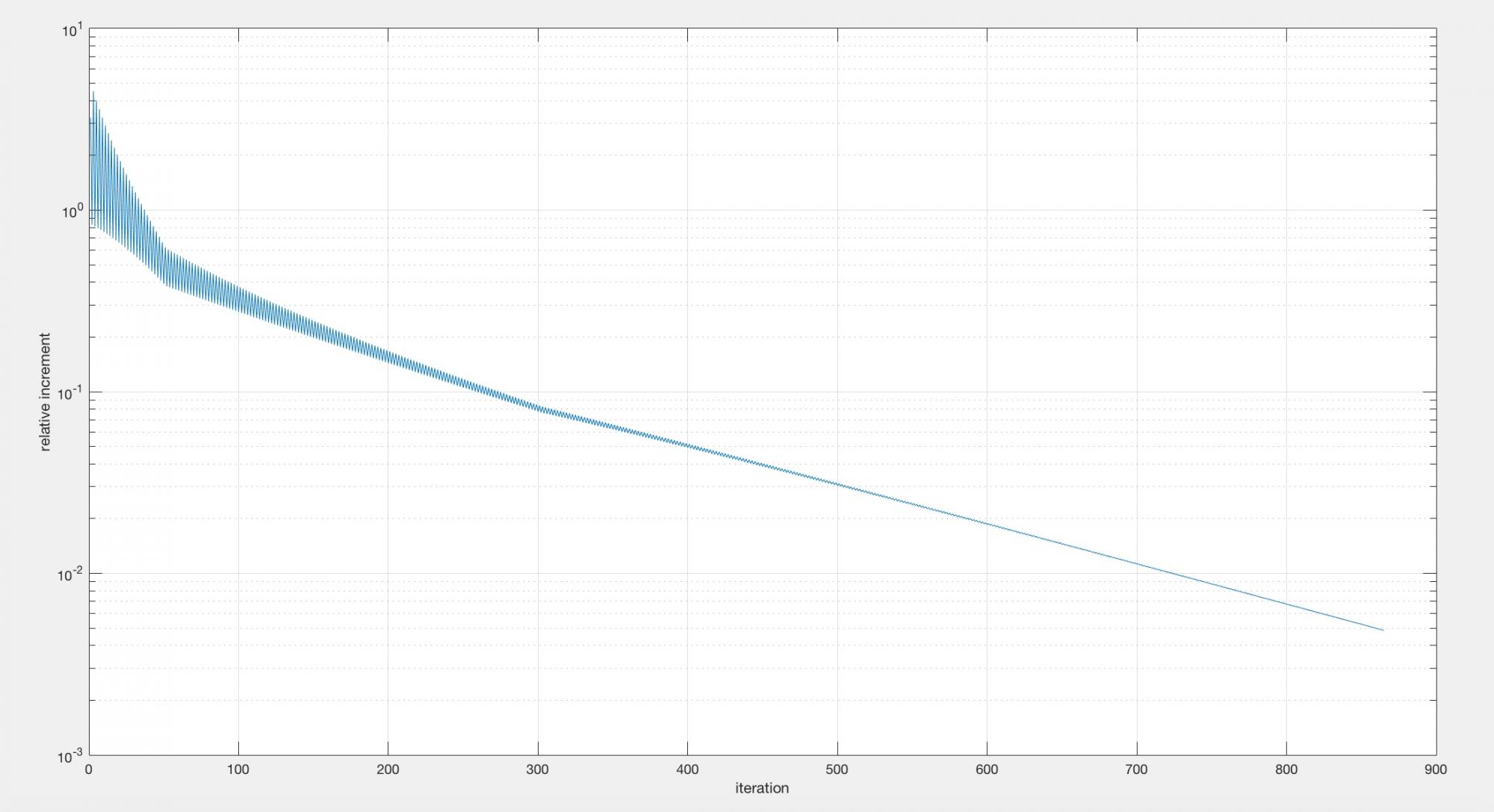
Après implémentation, le résultat est bien celui que j'attendais mais l'algorithme converge très lentement (j'atteins les 10^-3 de déviation relative autour de la 800ème itération là où je m'attends à pouvoir atteindre les 10^-9 en moins de 500...).
Je constate également un changement de taux de convergence étrange aux alentours de la 50ème itération.
Relative increment plot.jpg
J'aimerais beaucoup entendre vos conseils sur la manière d'accélérer la convergence de mon algorithme.
{kind=link}
{kind=link}
-----