

Bonjour à tous
J'aimerai comprendre pourquoi pour un même script, avec les mêmes données, le meme nombre d'epochs (ici 10 000), le meme learning rate etc..., il se peut qu'un réseau de neurone réussisse de bonnes predictions à l'epoch 2500 et soit excellent de l'epoch 2 500 a 10 000, et au run suivant, sans rien changer il n'arrive toujours pas a avoir de bonnes prédictions à l'epoch 10 000?
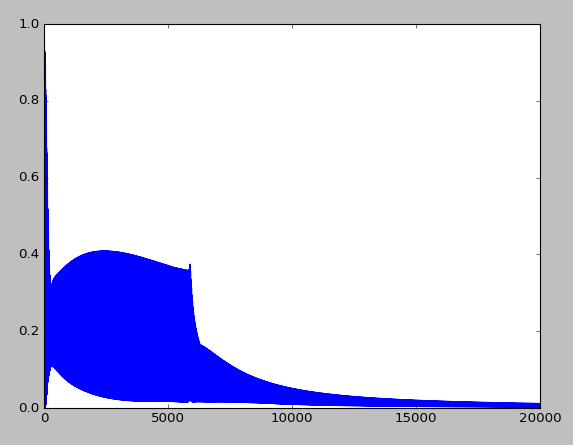
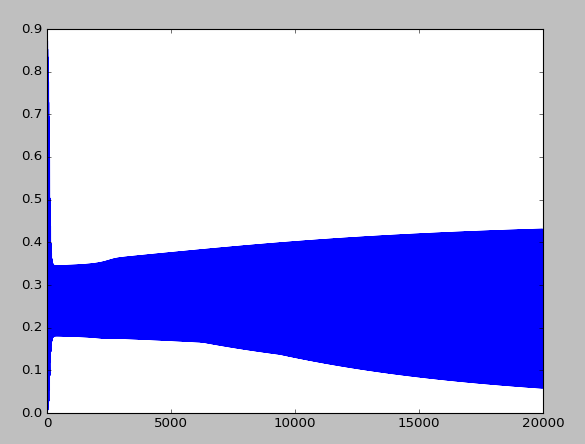
Je sais que les poids initiaux sont choisis aléatoirement, mais après tout le reste suit la meme loi, les mêmes corrections, dans le meme sens etc.... donc je comprendrai que au lieu d'avoir de bonnes predictions a l'epoch 2500 , cela commence a 3500 voir 4000 et ensuite suive le même type de courbe d'amelioration, mais là, mes courbes ((prediction-target)^2) vont avoir 2 à 3 tendances differentes selon le run (ca ressemble souvent a une des 3 mises en image en dessous, mais je comprend pas pourquoi tant de différences, surtout entre la 1 et la 2, on dirait que le réseau de neurone ne se comporte pas du tout de la meme façon
error_rate1.png
error_rate2.png
error_rate3.png
Merci
-----


{kind=link}
{kind=link}
{kind=link}