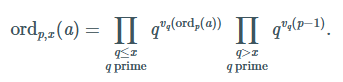Bonjour,
Quand ChatGPT est sorti, il était franchement très mauvais en maths et même pas en raisonnement, tout simplement en calcul. C'était normal vu la technologie et on sait que les réseaux de neurones ne sont pas bons pour compter comme d'ailleurs l'immense majorité des humains. C'est pour cela que depuis toujours, on a inventé des aides : bouliers, chiffres arabes et algorithmes, machines à calculer mécaniques puis électroniques, etc.
Mais beaucoup de progrès ont été faits, beaucoup de benchmarks qui semblaient difficiles conçus puis surmontés.
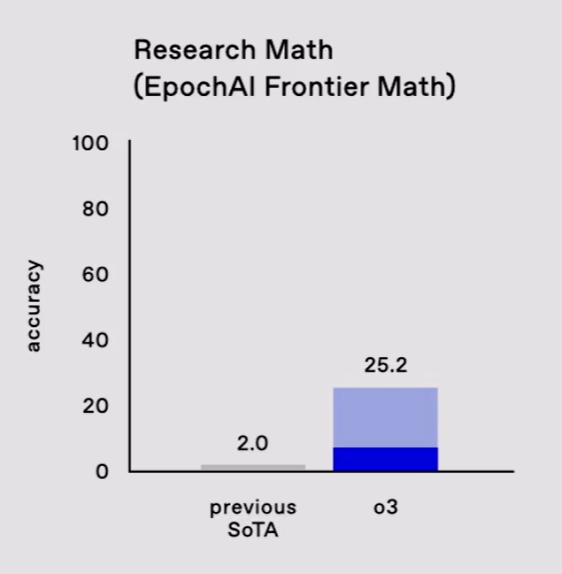
Donc très récemment, en novembre a été annoncé un nouveau benchmark considéré comme très difficile : https://epoch.ai/frontiermath/the-benchmark
On peut voir quelques exemples ici : https://epoch.ai/frontiermath/the-benchmark et si vous voulez, vous pouvez essayer de les résoudre si les commentaires des médailles Fields sur leur difficulté ne vous retiennent pas
Bref, aucune IA n'avait une performance supérieure à 2% de réussite.
O3 vient de faire 25% et vu le timing, ce n'est pas parce qu'il avait vu les réponses avant comme suggéré par la très remarquée et souvent mal interprétée étude d'Apple ici : https://arxiv.org/pdf/2410.05229
C'était juste pour partager cette information et donner une idée des progrès.
A titre indicatif, sur un autre benchmark, ARC-AGI (https://arcprize.org/arc), on était à 5% pour les meilleures IA début 2024, 32% en septembre ce qui est déjà impressionnant.
O3 est à 88% fin 2024.

-----