


Pour ce qui est de l'efficacité, en fait le principe du calcul partagé repose sur le fait qu'il y a beaucoup de données a traiter, et que la méthode de traitement est de regarder petit bout par petit bout,
Si ce n'est qu'une machine qui fait ce calcul, elle doit avoir fini un bout pour passer a l'autre.
L'interret de repartir est d'envoyer une parties des données a traiter par ordinateur, qui les traite, et qui renvoie a un 'central' les resultats du traitement des données qui lui ont été envoyées. Donc tout le monde bosse en meme temps sur différentes parties, donc extrêmement plus rapide...
Plus imagé: pour trouver quelque chose d'intéressant dans une grande image, 100 types lents iront plus vite a trouver cette chose intéressante qu'un seul type très rapide.
La pussance de calcul de chacun est importante, alors continuons (je regrette quand meme qu'il y ait pas plus de choses pour linux)
-----








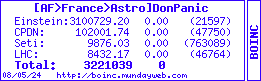
 tu vient pas souvent sur le forum de l'af ?...
tu vient pas souvent sur le forum de l'af ?...  ... mais apres un an d'inactiviter j'ai repris chez boinc ( l'af ... ) et cela m'a l'air stable ( 3 mois sans problemes en tout cas
... mais apres un an d'inactiviter j'ai repris chez boinc ( l'af ... ) et cela m'a l'air stable ( 3 mois sans problemes en tout cas  )
)

 )
) ) et rosseta maintenant !!!)
) et rosseta maintenant !!!)
 T'aurais pas un train ou deux de retard ?
T'aurais pas un train ou deux de retard ? 