
Hello,
Y a til des gens qui connaissent le Q Learning ici?
Jai quelques questions
Merci!
-----

Hello,
Y a til des gens qui connaissent le Q Learning ici?
Jai quelques questions
Merci!
Salut,
Oui il y en a qui connaissent (pas moi, je sais juste que ça existe mais je ne connais pas les détails).
Mais pose tes questions, sinon ça va être difficile d'y répondre
"Il ne suffit pas d'être persécuté pour être Galilée, encore faut-il avoir raison." (Gould)
Merci.
Bon ma première question était de savoir pourquoi on ne pouvait pas se contenter de travailler en exploration pure durant une premiére phase d'apprentissage, avec des actions aléatoires ne prenant pas en compte Q. La réponse était que parfois on peut le faire en effet, mais que certains problémes nécessite de réussir au moins un peu pour pouvoir explorer et apprendre d'autres actions.
Autre question:
Pourquoi a-t-on besoin du max(Q) dans l'équation de Bellman?
Ne peut-on pas seulement dire:
Q'=(1-alpha)Q + alpha.R
sans être un expert, il me semble que le maximum se prenne sur l'ensemble des actions possibles. Si tu as une seule action cela doit revenir a ne pas prendre de maximum mais dans ce cas je pense que ce n'est plus réellement du Q Learning non?Autre question:
Pourquoi a-t-on besoin du max(Q) dans l'équation de Bellman?
Ne peut-on pas seulement dire:
Q'=(1-alpha)Q + alpha.R
Pour la première partie, c'est un problème pour toute evaluation statistique. Tu as un problème de grande dimension, si tu parts de n'importe où dans un tel espace il faut que tu visite un volume gigantesque qui ne sert a rien avant de commencer a réellement visiter le sous espace d'intérêt. Faire une inférence statistique revient a restreindre l'espace des paramètres ajustés dans une zone de confiance de leur valeur d'une certaine manière. Je pense que c'est une réécriture de la phrase que tu mentionne:
Le soucis est que si ton points (vecteur a N dimension de tes parametres) correspond a mminimum local, tu vas ajuster des mauvais paramètres.La réponse était que parfois on peut le faire en effet, mais que certains problémes nécessite de réussir au moins un peu pour pouvoir explorer et apprendre d'autres actions.
Je ne sais pas si j'ai réellement répondu a tes questions. Des gens plus experts viendront certainement par la suite.
Oui c'est le max, mais ca ne m'explique pas pourquoi c'est nécessaire d'inclure ce terme, je ne vois pas pourquoi mon équation simplifiée ne marcherait pas. Je précise qu'avant de poster ici, j'ai du lire une dizaine de blogs sans comprendre ce point. Je vais peut-être simplement essayer de coder ca moi-même et voir ce que ca donne en pratique...Envoyé par physeb2

Oui, on est bien d'accord.
Tu as un ensemble d'actions que tu peux appliquer, mais tu garde l'action qui maximise le gain après feedback. Dans ton equation n'apparait pas explicitement les elements d'action que tu peux utiliser donc je ne peux pas vraiment comprendre ce que tu veux dire avec elle.Oui c'est le max, mais ca ne m'explique pas pourquoi c'est nécessaire d'inclure ce terme, je ne vois pas pourquoi mon équation simplifiée ne marcherait pas. Je précise qu'avant de poster ici, j'ai du lire une dizaine de blogs sans comprendre ce point. Je vais peut-être simplement essayer de coder ca moi-même et voir ce que ca donne en pratique.
Salut,
Merci pour ces explications instructives.
Un truc sympa là dessus qui se pose beaucoup depuis le "big data" :
https://fr.wikipedia.org/wiki/Fl%C3%...e_la_dimension
Qu'on appelle aussi le fléau des grandes dimensions. Je ne suis pas sûr que ce soit très utile pour la question initiale mais c'est plutôt intéressant.
Petit coucou à pm42 (que je sais bien connaitre ces sujets) : si tu passes, sais-tu expliquer pour le terme max(Q) a inclure dans l'équation ? (c'est un classique problème d'optimisation quand on regarde bien, mais je dois dire que là a priori je ne vois pas la réponse)
"Il ne suffit pas d'être persécuté pour être Galilée, encore faut-il avoir raison." (Gould)
Non, je ne sais pas là comme ça et je manque de temps pour creuser le sujet.
Cordialement.
Ok, merci, ça valait le coup de demander.
"Il ne suffit pas d'être persécuté pour être Galilée, encore faut-il avoir raison." (Gould)
Et ici je vois un développement plus détaillé avec "dérivation de l'équation" :
https://en.wikipedia.org/wiki/Bellman_equation
A voir si ça n'explique pas l'origine de ce terme.
ou ici peut-être : https://towardsdatascience.com/the-b...n-59258a0d3fa7
Mais je manque de temps pour creuser aussi ce sujet que je ne maîtrise pas (et comme je suis au boulot ....)
"Il ne suffit pas d'être persécuté pour être Galilée, encore faut-il avoir raison." (Gould)
Bah, en effet pas explicitement, mais j'utilise quand même le reward correspondant à l'action qui vient d'être effectuée, donc je supposais que cela suffisait pour augmenter le Q correspondant à cette combinaison particulière d'état- action, et donc à terme de choisir cette action avec une plus grande probabilité (resp. diminuer pour un mauvais reward). Ajouter le Max correspondants aux actions futurs me semble redondant, mais je n'ai aucun doute de n'avoir pas bien compris quelque chose....
Implémentation en cours...
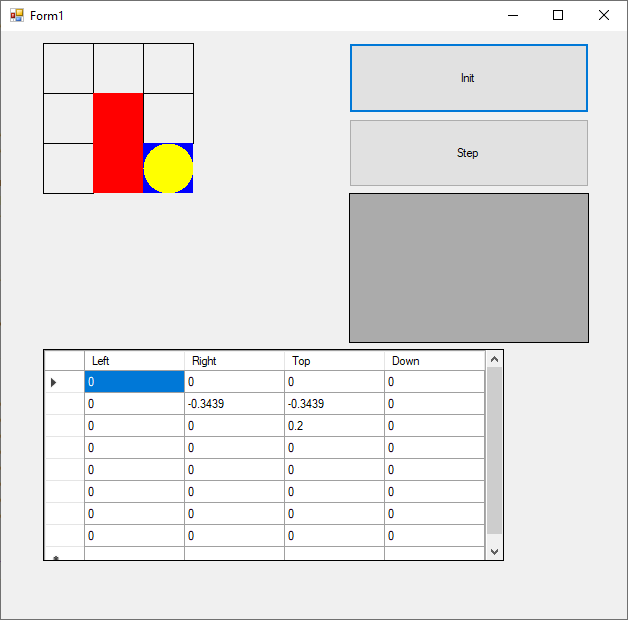
Bon, j'ai terminé mon implémentation, je pense que j'ai fait tous les bugs qu'il était possible de faire...
Le but de mon agent est d'aller jusqu'à la case bleue en bas à droite, sans passer par les cases rouges, en commençant de n'importe quelle case.
Le tableau Q ci-dessous est construit avec 9 lignes correspondants chacun aux 9 cases, en partant en haut à gauche.
Il a 4 colonnes correspondant chacun à un déplacement.
On peut voir ci-dessous, qu'après convergence, la valeur maximum de chaque ligne correspond à l'action optimale pour la case ou l'on se trouve. Donc c'est cool, ca marche.
Maintenant ma question initiale, c'est quoi ce Max dans l'équation, est-ce vraiment bien utile?
Bah oui...
Car la manière dont fonctionne le Q-Learning est d'indiquer à quel point l'action que l'on va effectuer sert notre objectif, et ce pour toutes les actions possibles de toutes les cases.
Or, ce n'est pas si évident, par exemple si on part en bas à gauche, comment savoir qu'il faut aller en haut? En fait, le seul moment où l'on sait où aller c'est quand on est juste au dessus la case bleue (faut aller en bas...).
Ce qu'il faudrait c'est que lorsqu'on est en haut à gauche, on ait une indication comme quoi la case d'en dessous, même si ce n'est pas notre objectif est en fait une "situation d'avenir"...
0_EezURPNjW2U6EYpA.jpeg
Et ben c'est exactement le but ce Max dans l'équation de Bellman, car il mesure à quel point l'état dans lequel on se retrouvera après avoir effectué une action est "prometteur". Et comme on met à jour ces valeurs de manière itératives, ces "situations d'avenir" se propagent à travers la matrice Q et finissent par indiquer que dans la case en bas à gauche, l'action vers le haut est la bonne...
Je dois dire que j'ai du lire une dizaine de sites avant de comprendre cela. Comme souvent sur Internet, il y a beaucoup de gens qui "expliquent" sans réellement avoir compris ce dont ils parlent (j'ai rencontré le même problème pour l'équation de Rietveld et j'ai du remonter à une publication des années 70 pour comprendre un terme de l'équation...), ce site va, lui, vraiment au fond des choses.
Par contre, je me rend maintenant compte de tout ce que je ne comprend pas sur la théorie sous-jacente, et en particulier sur les Hidden Markov Model...
Form1 9_18_2022 2_54_47 PM.png
PS: Les images ne s'affichent pas, j'ai tout essayé sans succés, le Q-Learning c'est plus simple...
{kind=link}
{kind=link}