

Bonjour,
Jai toujours eu du mal à comprendre pourquoi pour un CNA on définit le pas en divisant la pleine échelle par 2^n 1 alors quon divise par 2^n pour le CAN.
Je trouve aucune ressource expliquant cette différence. Jai donc creusé un peu le sujet et je suis arrivé à l*explication suivante. Jaimerais bien avoir un retour afin de savoir si je ne fais pas complètement fausse route. Merci
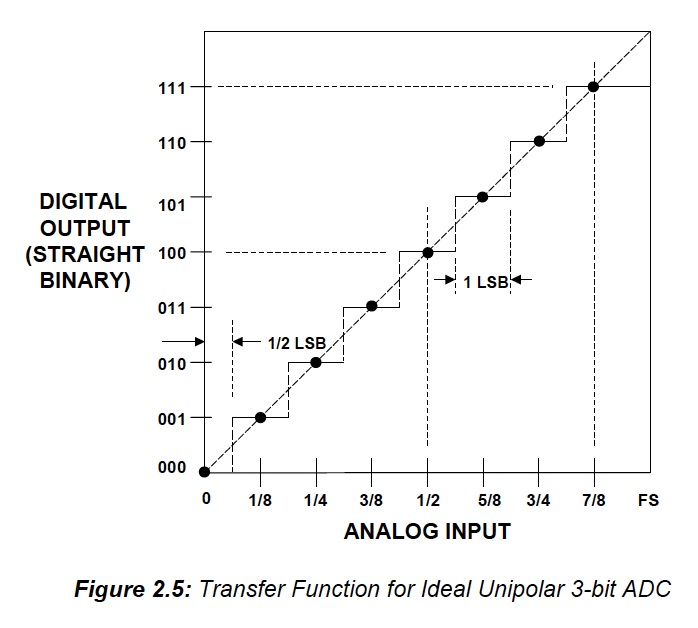
Je prends lexemple dune conversion sur 3 bits.
Pour le CAN*:
[0;1q[ → 000
[1q;2q[ → 001
[2q;3q[ → 010
[3q;4q[ → 011
[4q;5q[ → 100
[5q;6q[ → 101
[6q;7q[ →110
[7q;8q[ → 111
On découpe bien la plage de tension en 8 intervalles et on affecte une valeur numérique par plage de tension. La division par 2^n est évidente.
Pour le CNA*:
1) si je choisis deffectuer la conversion inverse en choisissant de diviser par 2^n aussi (et pourquoi pas??)*:
000 → 0q
001 → 1q
010 → 2q
011 → 3q
100 → 4q
101 → 5q
110 → 6q
111 → 7q
Ce qui fait que je sous estime systématiquement la valeur analogique dorigine de 1q au maximum*:
par exemple*:
- une tension de 0.9q est numérisée en 000 et sera restituée à 0q → on sous estime de 1q max
- une tension de 7.9q est numérisée en 111 et sera restituée à 7q → on sous estime de 1q max
- une tension de 3.9q est numérisée en 011 et sera restituée à 3q → on sous estime de 1q max
etc.
2) si je choisis un pas en divisant cette fois pas 2^n-1 (et pourquoi pas non plus?)*:
Alors par rapport au CAN jobtiens un nouveau pas q = 1.14q (environ)
000 → 0q = 0q
001 → 1q = 1.14q
010 → 2q= 2.29q
011 → 3q= 3.43q
100 → 4q= 4.57q
101 → 5q= 5.71q
110 → 6q= 6.86q
111 → 7q = 8q
à ce moment là*:
- une tension de 0.9q est toujours numérisée par le CAN à 000 et sera toujours restituée à 0q donc toujours une sous estimation de 1q max dans ce cas.
- une tension de de 7.9q est numérisée par le CAN en 111 et sera restituée à 7q=8q, cette fois ci on surestime de 1q max (ce qui nest pas vraiment plus grave..)
- En revanche, une tension de 3.9q numérisée en 011 sera restituée à 3q=3.43q soit environ au milieu de lintervalle et grosso modo on va avoir une erreur max de + ou 0.5q ce qui est mieux que dans le cas précédent où on sous-estime systématiquement de 1q max.
En résumé, je dirais que diviser par 2^n 1 dans le cas de la restitution permet de conserver une erreur max de 1q aux extrémités de la caractéristiques mais de réduire cette erreur à 0.5q (en plus ou en moins) au voisinage du milieu de la caractéristique. Ce qui est théoriquement mieux en effet.
Maintenant je rajouterais quand même quà partir dun certain nombre de bits, en pratique cette différence doit devenir très largement négligeable par rapport aux autres erreurs Donc pourquoi se casser la tête et ne pas diviser par 2^n dans tous les cas *?? Javoue que je nai pas de réponse là dessus
Merci de vos retours
-----



{kind=link}
{kind=link}